




 Thomas Thiel, 09/02/95
Thomas Thiel, 09/02/95
Introduction and System Topology
Introduction
During the recent years one can observe a trend towards MIMD (multiple instruction
multiple data) multiprocessor architectures. The scalability of these systems is
generally restricted by the number of processors accessing shared memory or by the
complexity of the interconnection network. We believe that these restriction can be
overcome by using distributed shared memory and an
interconnection network which has a constant local complexity independant of the
system size.
At the University of Erlangen-Nürnberg a concept was developed for a multiprocessor
project. This concept is based on the following characteristics:
- Communication between neighbouring nodes is achieved via dirtributed shared
memory.
- Each node has access to one or more of these memory modules.
- Two categories of memory exist: private memory, which is only accessible
by one node and communication memory, which is accessible by more nodes
(a multi-port memory).
- All nodes are designed equally.
- As far as possible off-the-shelf components should be used.
- Neighbouring nodes
- Two nodes are called neighbouring nodes, if they have access to the same
communication memory module.
- Joined nodes
- A set of nodes is called joined, if one can find for each pair of nodes
a chain of neighbouring nodes, via which the pair is connected.
In our multiprocessor concept only joined systems are examined. In such systems data
transport of any source to any destination is possible.
MEMSY was build to validate the concept.
Design goals
The MEMSY architecture was defined with the following design goals in mind:
- Scalability
- The architecture should be scalable with no theoretical limit. The communication
network should grow with the number of processing elements in order to accommodate
the increased communication demands in larger systems.
- Flexibility
- The architecture should be usable for a great variety of user problems.
- Efficiency
- The system should be based on state-of-the-art high performance microprocessors.
The computing power of the system should be big enough to handle real problems
which occur in scientific research.
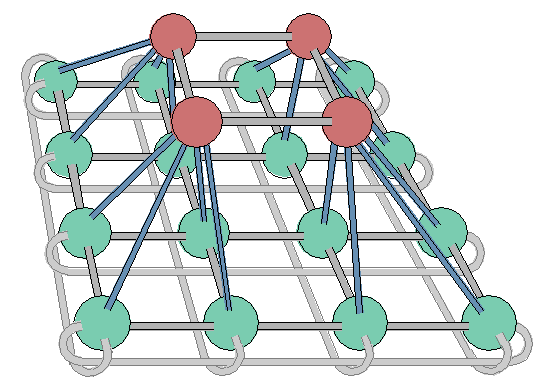
System Topology
The MEMSY structure consists of two planes. In each plane the processor nodes form a
rectangular grid. Each processor node has an associated shared-memory module, which is
shared with its four neighbouring processor nodes. The grid is closed to a torus. One
processing element of the upper plane has access to the shared-memory modules of the
four processing elements directly below it, thereby forming a small pyramid. There are
four times as many processing elements in the lower plane than in the upper.
On top of the whole system there is an optional processor which may serve as a
front-end to the system.
Thomas Thiel (thiel@informatik.uni-erlangen.de)