
LAOS: Latency Awareness in Operating Systems
Motivation
Self-made minimal kernels providing thread and interrupt management, as well as synchronization primitives are analyzed with respect to performance and scaling characteristics. These kernels consist of different architectural designs and alternative implementations. Strong focus lies on non-blocking implementations on parts, or if possible, on the whole operating system kernel. Standard Intel x86-64 compatible processors are the main target hardware because of their popularity in high-performance parallel computing, server and desktop systems. After careful analysis, modifications of existing kernels e.g. Linux may be possible that increase the performance in highly parallel systems.
People Involved in LAOS


Custom Kernels
Two operating system kernels were implemented, they serve twofold purposes:
- Analyzing the effects of different kernel architectures on the overall performance of the system.
- Analyzing the possibility of non-blocking synchronization in kernels and its effects on system performance.
LAKE has a multicore event-based architecture with a single kernel stack per CPU core. Whereas MAOS is a classical process-based kernel. Both kernels are non-blocking, meaning that all concurrent operations on data structures are carried out via atomic instructions of the CPU, no spinlocks where used. Both kernels provide an interface for the creation, management and synchronization of threads in a shared memory context.
Performance
Performance measurements with the use of the NAS parallel benchmarks are in preparation.
In addition custom parallel application benchmarks were carried out, comparing LAKE, MAOS and Linux on the same machine. Dijkstra searches for the shortest ways to all nodes in a graph from a certain start node. Jacobi solves a heat boundary value problem using Jacobi's iterative method. The measurement units are CPU clock cycles.
| Hardware: | Software: |
| AMD 6180SE 4x12 cores, 2.6 GHz 64GB RAM, 8 NUMA nodes |
GCC 4.7.2 Linux 3.2 |
| Dijkstra | Dijkstra Speedup |
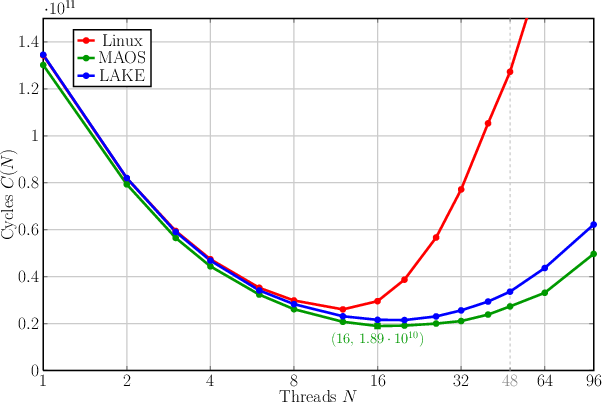
|
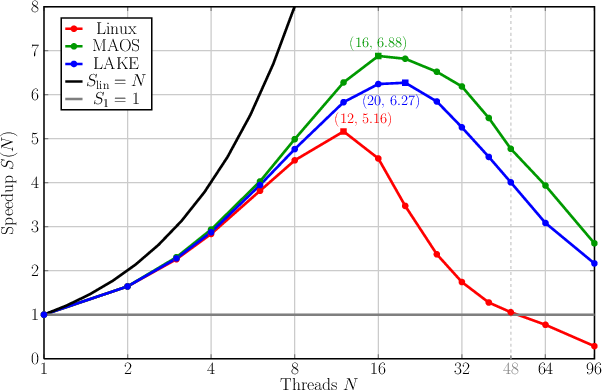
|
| Jacobi | Jacobi Speedup |

|
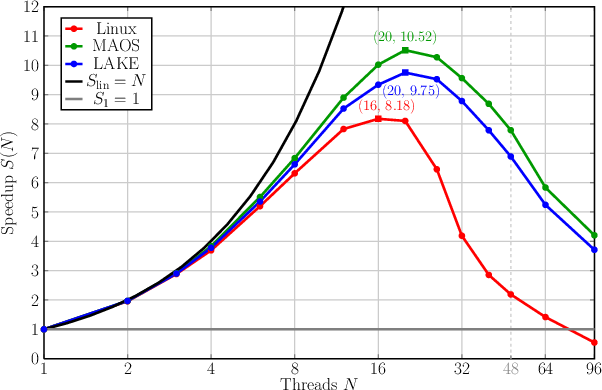
|
Linux
Reasons for the bad scaling characteristics of the Linux kernel are currently studied.Theses
Open Topics
Please feel free to contact gabor.drescher@cs.fau.de if you are interested in a bachelor or master thesis.Ongoing Theses
Finished Theses
- A NUMA-Aware Memory Distribution Strategy for the LAOS Kernel
- Bearbeiter: Jacob Denker (beendet am 31.10.2013 )
- Betreuer: Prof. i. R. Dr.-Ing. habil. Wolfgang Schröder-Preikschat, Dr.-Ing. Gabor Drescher, M. Sc.
- Leveraging Non-Blocking Synchronization in a Process-Based Many-Core OS Kernel
- Bearbeiter: Sebastian Maier (beendet am 28.03.2013 )
- Betreuer: Prof. i. R. Dr.-Ing. habil. Wolfgang Schröder-Preikschat, Dr.-Ing. Gabor Drescher, M. Sc., Dr.-Ing. Benjamin Oechslein
Publications
Reif, Stefan ; Herzog, Benedict ; Hügel, Fabian ; Hönig, Timo ; Schröder-Preikschat, Wolfgang:
Nearly Symmetric Multi-Core Processors.
In: ACM (Hrsg.) : Proceedings of the 11th ACM SIGOPS Asia-Pacific Workshop on Systems
(The 11th ACM SIGOPS Asia-Pacific Workshop on Systems, Tsukuba, Japan, 2020-08-24).
2020, S. 18.
Stichwörter: InvasIC; eLARN; LAOS (BibTeX)
Maier, Sebastian ; Hönig, Timo ; Wägemann, Peter ; Schröder-Preikschat, Wolfgang:
Asynchronous Abstract Machines: Anti-noise System Software for Many-core Processors.
In: ACM (Hrsg.) : Proceedings of the 9th International Workshop on Runtime and Operating Systems for Supercomputers (ROSS 2019)
(International Workshop on Runtime and Operating Systems for Supercomputers, Phoenix, June 25., 2019).
2019, S. 19-26.
Stichwörter: InvasIC; LAOS; AAM
[doi>10.1145/3322789.3328744] (BibTeX)
Drescher, Gabor ; Hönig, Timo ; Maier, Sebastian ; Oechslein, Benjamin ; Schröder-Preikschat, Wolfgang:
A Scalability-Aware Kernel Executive for Many-Core Operating Systems.
In: S. Lankes ; C. Clauss (Hrsg.) : Proceedings of the 1st Workshop on Runtime and Operating Systems for the Many-core Era
(ROME 2013, Aachen, August 26, 2013).
Berlin-Heidelberg : Springer-Verlag, 2013, S. 823-832. (Lecture Notes in Computer Science (LNCS))
Stichwörter: LAOS
[doi>10.1007/978-3-642-54420-0_80] (BibTeX)